Siden jeg startede med at bruge Home Assistant, har jeg brugt MariaDB som min database. Jeg kører Home Assistant og database på samme server, som er en Intel i7-13700K maskine med 64GB RAM.. bare fordi. Den bruges naturligvis også til andet.
Jeg hader ikke at have styr på min data, så da jeg startede med Home Assistant og de introducerede recorder, valgte jeg naturligvis at sige, at recorder ikke skulle slette (purge) noget data, da jeg bare ville gemme alt.. for hvor meget kan sådan noget fylde??
Fast forward et par år, hvor vi i mellemtiden også har fået solceller, hvor inverteren opdaterer data hvert sekund, så har det åbenbart hobet sig så meget op, at jeg endte med over 500 millioner rækker i min database. 500.000.000 rækker. Jeg kunne på hvilket som helst tidspunkt gå tilbage og se, hvor hurtigt jeg kørte i bilen, hvor meget huset brugte af strøm osv. Ned til 1 sekund opløsning. Det gjorde at min database endte med at fylde små 300 gigabyte, og min stakkels server ikke kunne følge med længere, til trods for at jeg smed 16GB RAM efter MariaDB – kun til databasen. Jeg valgte at slette omkring 350 millioner rækker, som tog et par dage selvom det var automatiseret, og gøre så recorder kun gemmer rå data i 90 dage, hvorefter det automatisk bliver sat ned i opløsning, så det i stedet for er gennemsnittet for en time (mener jeg).
Det hjalp gevaldigt, men jeg synes stadigvæk det tog lang tid at indlæse energy dashboard, hvis jeg ville have data for flere måneder osv. Derfor har jeg nu besluttet at migrere til PostgreSQL – og holy fucking shit det går stærkt. Jeg har stadigvæk omkring 150 millioner rækker i min database, men se lige hvor hurtig den er:
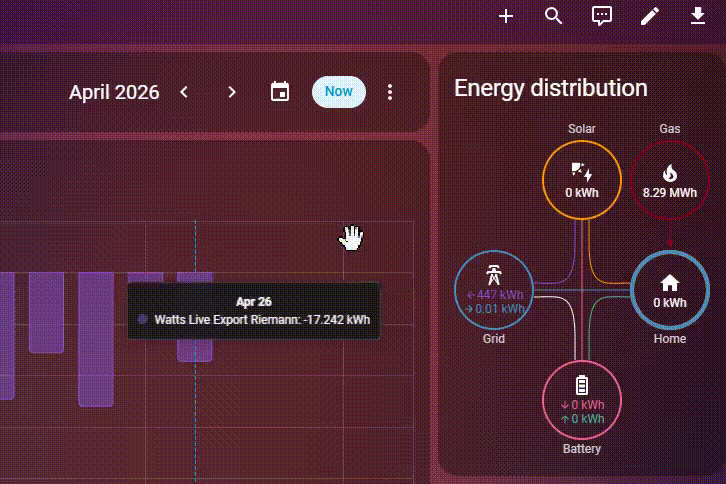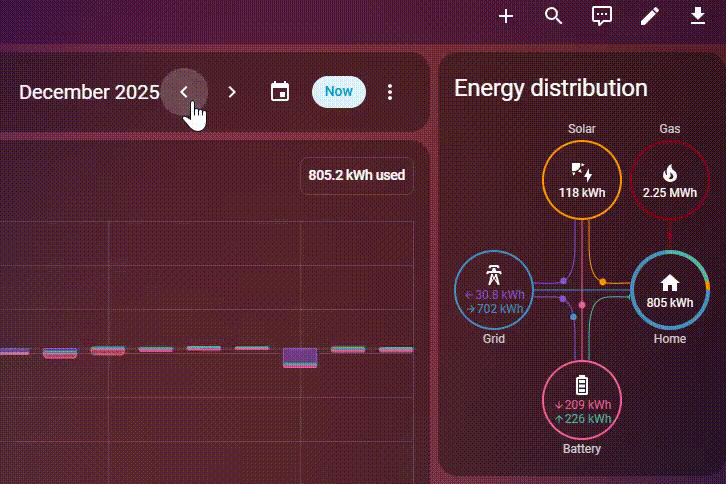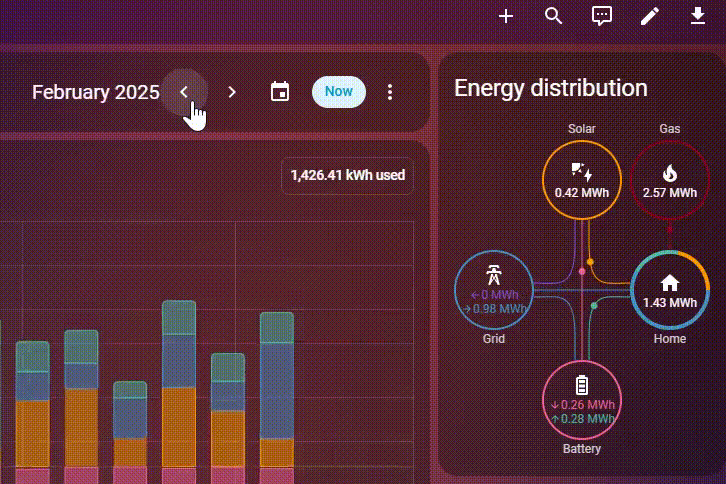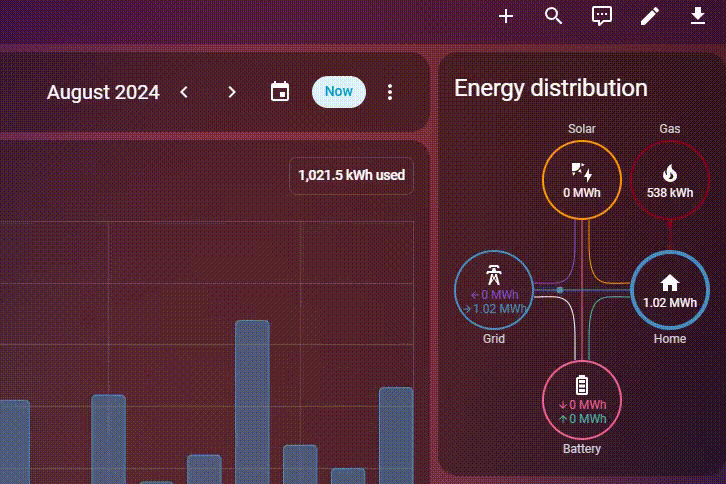
Hvordan?
Jeg startede med at spinne en postgres:18 database op i en Docker container, oprette en bruger specifikt til Home Assistant, og så oprette en database der hedder homeassistant. Brug eksempelvis pgAdmin værktøjet til at logge ind og gøre dette.
Derefter spinnede jeg en Ubuntu 26.04 container op i Docker og kørte apt update && apt install -y pgloader for at installere pgloader. pgloader bruges til at kopiere data 1:1 fra én kilde til Postgres. I mit tilfælde fra MariaDB til Postgres.
Derefter oprettede jeg to filer. Den ene bruges til at oprette tabellerne og kopiere dataen. Den anden står for at lave indexes. Årsagen til dette var, at jeg oplevede databasen døde på grund af overload, da den kopierede data imens et index var ved at blive oprettet. Opret derfor disse to filer:
migrate-db.load
LOAD DATABASE
FROM mysql://morten:password@192.168.1.56:3306/homeassistant
INTO postgresql://homeassistant:homeassistant@192.168.1.56:5432/homeassistant
WITH
include drop,
create tables,
reset sequences,
foreign keys,
workers = 4,
concurrency = 2,
multiple readers per thread,
rows per range = 20000
SET
maintenance_work_mem to '512MB',
work_mem to '64MB'
ALTER SCHEMA 'homeassistant' RENAME TO 'public';create-indexes.load
LOAD DATABASE
FROM mysql://morten:password@192.168.1.56:3306/homeassistant
INTO postgresql://homeassistant:homeassistant@192.168.1.56:5432/homeassistant
WITH
create indexes,
workers = 2,
concurrency = 1
SET
maintenance_work_mem to '1GB';Alt afhængig af specs på maskinen, skal du måske justere de memory indstillinger, dog vil jeg vurdere de er meget konservative og stressede overhovedet ikke min server. Ret IPen så den matcher din maskine, eller prøv localhost og se om det virker (kræver dog din Docker container ved at localhost er din host og ikke den selv). Indsæt selv username og password til dine databaser.
Kør derfor begge scripts, dog i rækkefølge og kør kun create-indexes.load når migrate-db.load er færdig:
pgloader --debug --dynamic-space-size 8192 migrate-db.load
pgloader --debug --dynamic-space-size 8192 create-indexes.loadDerefter er det blot et spørgsmål om at rette din Home Assistant configuration.yaml til at pege på Postgres, hvor du kan tage udgangspunkt i min recorder opsætning:
recorder:
db_url: "postgresql://homeassistant:homeassistant@192.168.1.56:5432/homeassistant"
commit_interval: 30
auto_purge: true
auto_repack: true
purge_keep_days: 90Og så genstarter du bare Home Assistant og så virker det! Husk at tjekke loggen efter fejl, for Home Assistant skal nok fortsætte og køre som normalt, men data bliver gemt i memory og bliver aldrig gemt til databasen, hvis der er en fejl.
Noget man skal være opmærksom på?
Ja, sådan er det jo altid med databasemigrering. Fra du kalder første pgloader kommando, skal du forvente at al data går tabt indtil du har genstartet Home Assistant, hvor du peger over på den nye database. Jeg har desværre ikke fundet en god måde at tilføje en form for WHERE id > 123456 clause til pgloader, så man kan køre et ny “sync database” script, lige inden man starter Home Assistant op. Det tog mig 20 minutter at flytte alle 125.000.000 rækker OG oprette alle index, så for mig at se har jeg mistet 20 minutter data en søndag aften, så det var ikke ret spændende data alligevel.
Husk desuden backup. Jeg tog ikke bare en kopi af min MariaDB mappe og gemte den i skyen, men kørte derimod et script sammen med backup, der faktisk tager et dump af databasen. Sørg for at opdatere så Postgres gør det samme. Jeg brugte mariadb-dump før, men nu bruger jeg pg_dump. Begge er kommandoer MariaDB og Postgres containerne kender.
Tweak desuden dine Postgres config filer. Jeg brugte et fedt værktøj til at finde nogle indstillinger til min maskine, dog har jeg ikke givet den fuld smadder på alle 16 kerner, 24 tråde og 64GB RAM. Værktøjet finder du her og hedder PGTune: https://pgtune.leopard.in.ua/
Gode kommandoer at kende
Diskforbrug per tabel (sådan cirka i hvert fald)
SELECT
relname AS table,
pg_size_pretty(pg_total_relation_size(relid)) AS size
FROM pg_catalog.pg_statio_user_tables
ORDER BY pg_total_relation_size(relid) DESC;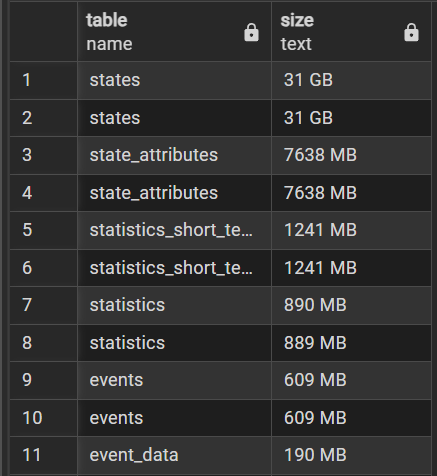
Antal rækker og største ID for primary key tilpasset til Home Assistant
SELECT 'event_data' AS table_name, count(*) AS row_count, max(data_id) AS max_id FROM event_data
UNION ALL SELECT 'event_types', count(*), max(event_type_id) FROM event_types
UNION ALL SELECT 'events', count(*), max(event_id) FROM events
UNION ALL SELECT 'recorder_runs', count(*), max(run_id) FROM recorder_runs
UNION ALL SELECT 'schema_changes', count(*), max(change_id) FROM schema_changes
UNION ALL SELECT 'state_attributes', count(*), max(attributes_id) FROM state_attributes
UNION ALL SELECT 'states', count(*), max(state_id) FROM states
UNION ALL SELECT 'states_meta', count(*), max(metadata_id) FROM states_meta
UNION ALL SELECT 'statistics', count(*), max(id) FROM statistics
UNION ALL SELECT 'statistics_meta', count(*), max(id) FROM statistics_meta
UNION ALL SELECT 'statistics_runs', count(*), max(run_id) FROM statistics_runs
UNION ALL SELECT 'statistics_short_term', count(*), max(id) FROM statistics_short_term
ORDER BY table_name;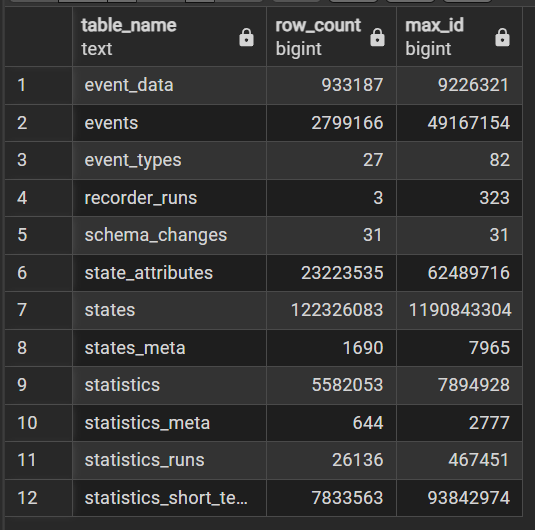
Skriv et svar